
Entwurf eines agentischen KI Systems für eine regulierte Branche
Einführung von grundlegenden Begriffen

Lieber Leser,
ich lerne zur Zeit wie man agentische KI Systeme designed. Dieser Artikel ist ein Brainstorming, ein Entwurf. Am Ende des Artikels interessiert mich Deine Meinung: Was hast Du verstanden? Was ist unklar? Was würdest Du anders machen? Let’s discuss!
Der Use Case ist willkürlich gewählt.
Der Use Case
Ausgangslage
Ein Investmenthaus veröffentlicht jedes Jahr verschiedene Publikationen: Factsheets, Quartalsberichte, Monatsbriefe, Nachhaltigkeitsreports, Offenlegungen, Webinare, FAQs. Jede Publikation durchläuft denselben Prozess. Daten zusammenziehen, Text schreiben, Compliance prüfen, freigeben lassen, bei Bedarf übersetzen. Die Stimme muss authentisch bleiben. Jede Abweichung vom eigenen Stil wird von den Kunden bemerkt.
Heute verbringen Portfoliomanager Tage vor jeder Publikation. Bei zeitkritischen Events wie starkem Kursverfall oder Marktumbruch muss innerhalb von Stunden transparente Kommunikation an die Anleger raus. Genau der Moment, in dem das Team am meisten gebunden ist.
Die Vision aus Sicht des Portfolio Managers
“Als Portfolio Manager gebe ich an, welche Publikation ich brauche: Factsheet, Quartalsbericht, Monatsbericht, Drawdown-Kommunikation. Ich gebe den Zeitraum an und die Sprache. Dann starte ich den Prozess.
Innerhalb von Minuten liegen mir die richtigen Zahlen vor. Renditen, Risikokennzahlen, Zusammensetzung, ESG-Metriken. Aus den richtigen Systemen, für den richtigen Zeitraum, konsistent geprüft. Ich muss nicht selbst vier Datenquellen abfragen und in eine Tabelle bringen.
Auf Basis dieser Zahlen entsteht ein Textentwurf. In unserer Tonalität. Nüchtern, ehrlich, erklärend. Bei guten Quartalen zurückhaltend. Bei schwierigen transparent und selbstkritisch. Nie werblich. Jede Zahl im Text hat eine nachvollziehbare Quelle.
Falls der Report in einer weiteren Sprache erscheinen muss, wird übersetzt. Nicht wörtlich, sondern mit Verständnis für regulatorische Nuancen.
Bevor ich den Report sehe, wurde er bereits gegen regulatorischen Anforderungen geprüft. SFDR, BaFin, FNG. Keine Performance-Versprechen, korrekte Formulierungen, vollständige Risikohinweise. Diese Prüfung ist regelbasiert und reproduzierbar.
Was ich dann sehe: Den fertigen Report. Daneben die vollständige Prüfung mit jeder angewandten Regel und jedem Ergebnis. Und die Quellennachweise für jede Zahl und jede Formulierungsentscheidung. Ich prüfe nicht mehr meinen eigenen Text. Ich prüfe die Arbeit eines Systems, das ich von außen beurteilen kann.
Woran ich erkenne, dass es gut geworden ist: Jede Zahl ist bis zur Datenquelle rückverfolgbar. Jede Formulierung ist begründet. Die regulatorische Prüfung ist vollständig dokumentiert. Der Text klingt nach uns, nicht nach einer KI. Und ich habe für die Stellen, die Urteilskraft erfordern, tatsächlich Zeit.
Die Zeit, die ich für die manuelle Erstellung benötigt hätte, verkürzt sich drastisch. Ich kann nicht nur den Text reviewen, sondern auch wie der Text zusammengestellt wurde.”
Bevor ich darauf eingehe, wie ein agentisches KI System gebaut sein müsste, das diese Vision Wirklichkeit werden lässt, zunächst ein paar grundlegende Begriffe.
Grundbegriffe: Workflows und Patterns
Ich beziehe mich im weiteren Verlauf auf diese Quelle:https://www.anthropic.com/engineering/building-effective-agents
Anthropic unterscheidet zwischen Workflows und Agents. In einem Workflow werden LLMs durch vordefinierte Code-Pfade orchestriert. Der Ablauf steht fest. In einem Agent steuert das LLM seinen eigenen Prozess dynamisch. Es entscheidet selbst, welchen Schritt es als nächstes macht.
Anthropic beschreibt sechs Patterns für agentische Systeme. Fünf davon nutzen wir in diesem Use Case. Eines bewusst nicht.
Building Block: The Augmented LLM
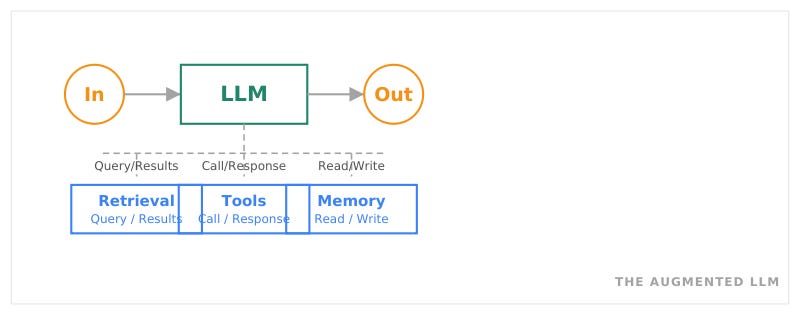
Building Block: The Augmented LLM
Quelle: Anthropic, Building Effective Agents, Dez 2024
Ein LLM mit Zugang zu externen Werkzeugen: Datenabfragen, API-Calls, Speicher. Der Grundbaustein jedes agentischen Systems.
Prompt Chaining
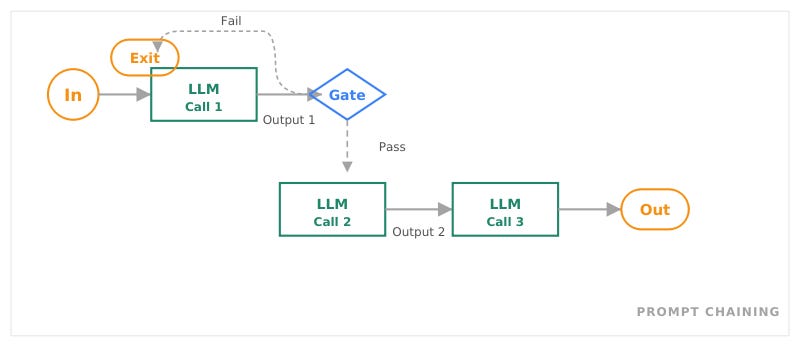
Prompt Chaining
Quelle: Anthropic, Building Effective Agents, Dez 2024
Eine feste Kette von LLM-Aufrufen. Jeder Schritt bekommt den Output des vorherigen. Zwischen den Schritten kann ein Gate prüfen, ob das Ergebnis weiterverarbeitet werden darf. Ideal für Aufgaben, die sich sauber in feste Unterschritte zerlegen lassen.
Routing
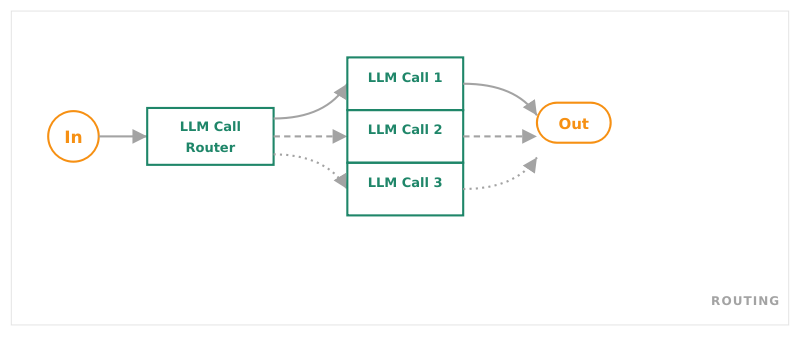
Routing
Quelle: Anthropic, Building Effective Agents, Dez 2024
Ein Router entscheidet, welcher Pfad eingeschlagen wird. Unterschiedliche Eingaben führen zu unterschiedlichen Verarbeitungsketten.
Parallelization
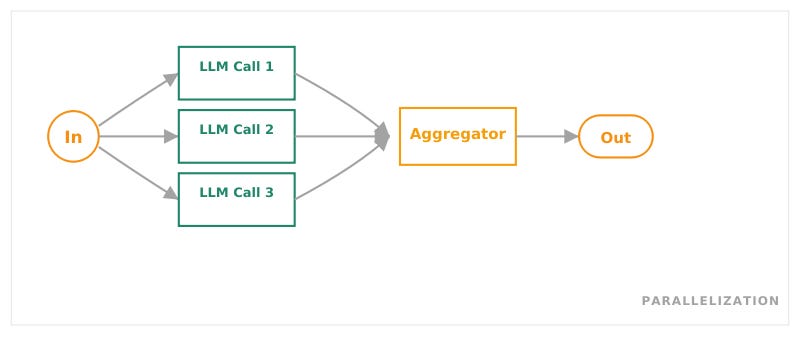
Parallelization
Quelle: Anthropic, Building Effective Agents, Dez 2024
Mehrere unabhängige Aufrufe laufen gleichzeitig. Die Ergebnisse werden am Ende zusammengeführt. Sinnvoll, wenn die Teilaufgaben keine Reihenfolge brauchen.
Evaluator-Optimizer
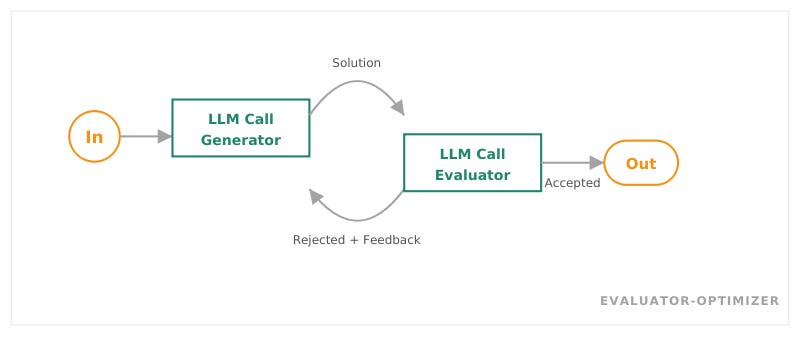
Evaluator-Optimizer
Quelle: Anthropic, Building Effective Agents, Dez 2024
Ein Generator erzeugt eine Lösung. Ein Evaluator prüft sie. Bei Ablehnung geht die Lösung mit Feedback zurück an den Generator. Der Loop wiederholt sich, bis die Lösung akzeptiert wird oder eine maximale Anzahl Versuche erreicht ist.
Autonomous Agent (in diesem Use Case bewusst nicht genutzt)
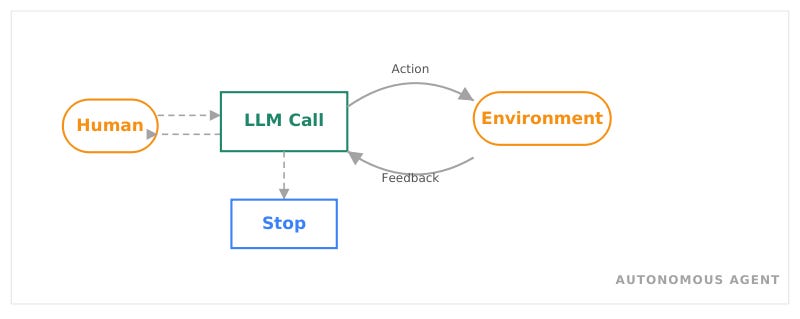
Autonomous Agent
Quelle: Anthropic, Building Effective Agents, Dez 2024
Das LLM steuert seinen eigenen Prozess. Es entscheidet, welche Aktion es ausführt, interpretiert das Feedback und entscheidet, ob es weitermacht oder stoppt. Der Mensch greift nur bei Bedarf ein. Warum dieses Pattern in diesem Use Case nicht genutzt wird, erläutert Sektion 5.
Der Architektur Draft
Warum ein Workflow und kein Agent?
Dieser Use Case ist kein kreativer Prozess wie es beispielsweise beim Schreiben eines belletristischen Textes der Fall wäre. Die Berichte müssen bestimmte regulatorische Anforderungen erfüllen.
Das LLM darf in diesem Use Case nicht entscheiden, wie der Prozess abläuft. Es darf nicht plötzlich eine zusätzliche Analyse einbauen, einen Schritt überspringen oder eine andere Struktur wählen. Der Prozess muss vorhersagbar, auditierbar und reproduzierbar sein. Dieser Use Case ist ein Workflow.
Der Graph
Der Use Case kombiniert vier Patterns: Prompt Chaining als Hauptmuster, Routing im Guardian, Parallelization im DataAgent und Evaluator-Optimizer als Guardian-Writer-Loop.
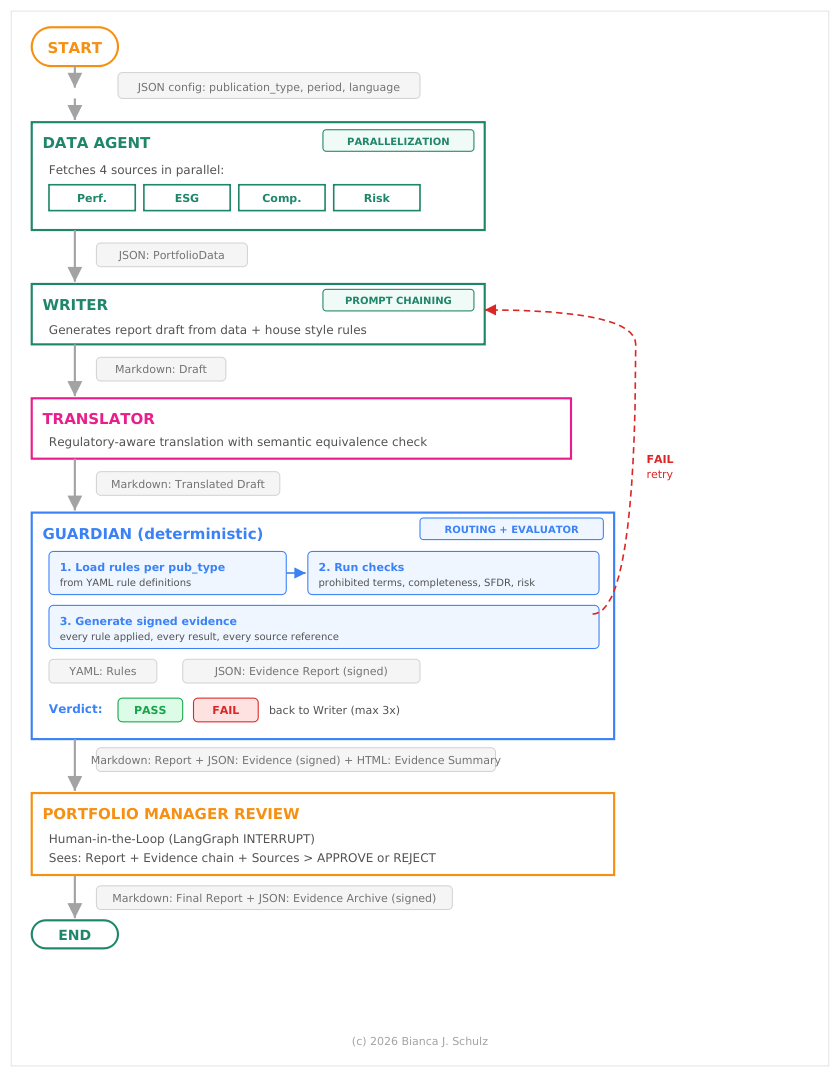
Use Case Architecture
Die Architekturentscheidungen im Entwurf
Prompt Chaining als Hauptmuster. Die Reihenfolge des Prozesses ist fest: Zuerst Zahlen holen, dann Text formulieren, dann bei Bedarf übersetzen, dann Compliance prüfen, dann freigeben. Schritt 4 kann logisch nicht vor Schritt 2 kommen. Jeder Schritt ist einfacher als die Gesamtaufgabe.
Deterministischer Guardian statt LLM-Evaluator. Ein LLM als Evaluator wäre nicht reproduzierbar. Dieselbe Eingabe könnte bei zwei Aufrufen unterschiedliche Ergebnisse liefern. Für eine BaFin-Prüfung wäre das schwierig. Der Guardian soll bei identischem Input immer dasselbe Urteil fällen. Deshalb ist der Guardian kein LLM. Er ist regelbasiertes Routing: pro Publikationstyp ein festes Regelset.
Parallelization im DataAgent. Der DataAgent ruft vier unabhängige Datenquellen parallel auf: Performance, ESG, Composition, Risk. Das ist Sectioning innerhalb eines Nodes. Der Graph bleibt linear.
Kein Orchestrator-Worker, kein Autonomous Agent. Orchestrator-Worker wird verwendet, wenn Subtasks nicht vorhersagbar sind. Hier sind alle Subtasks bekannt. Ein Autonomous Agent wäre kontraproduktiv. Entscheidungsfreiheit in regulierter Umgebung ist das, was man vermeiden will.
Warum keine autonomen Agenten
Die aktuelle Diskussion dreht sich oft um autonome KI-Agenten. Agenten, die ihre eigenen Prozesse steuern, eigene Entscheidungen treffen, eigene Tools auswählen. Das klingt nach Fortschritt. In regulierten Domänen ist es das schwierig.
Verhaltensdrift. Ein autonomer Agent kann sein Verhalten über die Zeit verändern, ohne dass sich sein Code ändert. Andere Trainingsdaten, andere Gewichte, ein Modell-Update. Das Paper AI Agents Under EU Law (Nannini et al., 2026)1 stellt fest: Hochrisiko-Agentensysteme mit nicht nachverfolgbarem Verhaltensdrift können die wesentlichen Anforderungen des AI Act derzeit nicht erfüllen.
Kontamination zwischen Agenten. Wenn Agenten in natürlicher Sprache miteinander kommunizieren, entsteht ein Kopplungskanal, der in keinem Einzelagenten-Test sichtbar ist. Die Kopplung ist messbar, aber unsichtbar für klassische Evaluation. In einem Compliance-Kontext ist unsichtbare Kopplung inakzeptabel.
Keine beweisbare Reproduzierbarkeit. Gleicher Input, gleicher autonomer Agent, zwei verschiedene Tage: potenziell zwei verschiedene Ergebnisse. Für eine BaFin-Prüfung, für einen FNG-Audit, für eine SFDR-Offenlegung ist das nicht hinnehmbar.
Workflow statt Agent ist kein Rückschritt. Es ist eine architektonische Entscheidung, die aus der Domäne folgt. Die Frage ist nicht: Wie viel Autonomie kann ich meinem Agenten geben? Die Frage ist: Wie viel Autonomie erlaubt die Domäne? In Compliance-Reporting lautet die Antwort: keine für Entscheidungen. Formulierung ja. Entscheidung nein.
Warum ein KI System sich trotzdem lohnt für diesen Use Case
Die bisherigen Sektionen beschreiben Einschränkungen. Man könnte fragen: Warum dann überhaupt KI einsetzen?
Die Datenarbeit ist mechanisch, aber aufwändig. Vier Datenquellen abfragen, Zahlen zusammenführen, Konsistenz prüfen, in ein Template gießen. Das macht heute ein Mensch. Es dauert Stunden. Ein DataAgent erledigt das in viel kürzerer Zeit.
Die Textarbeit ist kreativ, aber in engen Grenzen. Ein Quartalsbericht ist kein Roman. Die Struktur steht fest. Die Tonalität steht fest. Was variiert, sind die Zahlen und die Interpretation. Der Portfolio Manager korrigiert nicht mehr den gesamten Text. Er korrigiert die Stellen, die Urteilskraft erfordern.
Die Prüfung wird gründlicher. Heute prüft der Portfolio Manager seinen eigenen Text. Mit diesem Workflow prüft der Guardian zuerst. Deterministisch. Vollständig. Der Portfolio Manager prüft dann die Arbeit eines Systems, das er von außen beurteilen kann.
Die Reaktionszeit bei Krisen sinkt drastisch. Starker Kursverfall am Montagmorgen. Der Portfolio Manager hat innerhalb kurzer Zeit einen geprüften Entwurf vor sich. In einer Krise ist das der Unterschied zwischen reagieren und getrieben werden.
Die Zeit der Erstellung wird drastisch verkürzt, weil die KI die mechanischen Teile übernimmt und der Portfolio Manager sich auf das konzentriert, was nur er kann: urteilen, entscheiden, verantworten.
Die nächsten Schritte
Dieser Artikel hat noch nicht vollständig die Governance betrachtet und wie man sie gelöst.
Ebenso stellt sich die Frage, welche LLMs man für welchen Schritt verwendet und wo diese gehostet sind.
Außerdem wurde noch nicht erklärt wie man Daten zieht, Kontext baut, ein Gedächtnis aufbaut und Learning Loops codifziert.
Das kommt alles in Folgeartikeln.
Fazit
Auf jeden Fall habe ich beim Erarbeiten dieses Artikels sehr viel gelernt. Wie ging es Euch?
Die ganze Debatte um agentische KI Systeme hat sich für mich vollständig entmystifiziert.
Mir ist klar geworden, dass AI Systeme zu bauen eine Kombination ist aus dem Verstehen des Users, des Ziels, des gewünschten Outcomes, der Daten, des Kontexts, des Business Workflows und der Art und Weise wie man Workflows und Agenten mit KI baut.
Das Bauen von agentischen KI Systemen hat übrigens sehr viel Ähnlichkeit mit Software Engineering und Software Architektur. Ein LLM ist Teil eines Patterns und ein Pattern erinnert sehr stark an eine Funktion in einem Software Code.
Die Disziplinen rücken meiner Meinung nach näher zusammen, die Grenzen zwischen Technologie und Business kann man kaum noch ziehen, es ist EIN Konstrukt.
Dieses Verständnis ist wichtig um sich ein Bild davon machen zu können wie sich die Organisation und die Arbeitsweise ändern wird, denn erst wenn ich verstehe, was ich wie baue, kann ich entscheiden wen ich dafür benötige und warum.
Ich freue mich auf Eure Kommentare!
https://arxiv.org/pdf/2604.04604
Hallo Bianca,
ein erfrischend strukturierter Entwurf! Es ist wohltuend zu sehen, dass jemand den Hype beiseitelegt und versteht, dass Autonomie in einer regulierten Branche ohne harte, deterministische Leitplanken im Chaos endet.
Drei Sollbruchstellen sehe ich in der Praxis dennoch:
1. Modell-Drift: Ein Graph auf Basis externer Cloud-Modelle fängt deren permanente Instabilität und qualitative Schwankungen nicht ab. Insbesondere bei Closed Source.
2. Kontext-Kontamination: Ohne eine strikte, nicht-linguistische Abriegelung der Kommunikationswege zwischen den Domänen droht ein schleichender Kontaminationsprozess.
3. Intention-Layer: Ohne konkrete Validierung der Anforderung ist der Raum für Missinterpretationen durch das GPT weit offen.
Du hast eine hervorragende Brücke gebaut, aber die härtesten Nüsse warten an den architektonischen Endpunkten. Das ist übrigens genau der Punkt, an dem nahezu alle Agentensysteme in der Praxis scheitern.
Dein Kernsatz — ‚Workflow statt Agent ist kein Rückschritt, sondern eine architektonische Entscheidung, die aus der Domäne folgt' — beschreibt etwas, das ich aus 15+ Jahren Projektarbeit in Automotive und Bahntechnik kenne, lange bevor es agentische KI gab. Auch ein Projektteam darf dort den Prozess nicht frei ‚entscheiden' — die Gates stehen fest, weil zwei Jahre später ein Auditor den Entscheidungspfad nachläuft. Das ist kein Misstrauen gegen das Team, sondern die Einsicht, dass Nachvollziehbarkeit selbst ein Lieferergebnis ist. Genau deshalb überträgt sich deine Architektur 1:1: In regulierten Domänen ist der Freiheitsgrad eines Systems nie die Frage — die Beweisbarkeit seines Wegs ist es.
Dass du den Guardian bewusst regelbasiert hältst, damit er immer gleich urteilt — das finde ich genau richtig. Eine Frage habe ich trotzdem: Der Writer, der den Text erzeugt, ist ja weiter eine KI. Und eine KI schreibt denselben Text selten zweimal exakt gleich, auch bei gleichem Input. Der Ablauf ist also immer derselbe und sauber nachvollziehbar — das fertige Ergebnis kann sich aber von Lauf zu Lauf unterscheiden. Reicht einem Auditor, dass der Prozess immer gleich lief — oder will er, dass gleicher Input auch zweimal exakt dasselbe Ergebnis bringt?