
AI models
a small overview

This article is available in English and German.
Dear Reader,
after I had researched the different models, I thought: this topic is so banal, it’s not even worth an article. There are different models for different purposes, you don’t need to modify them, this is how you call them. Done.
I’m publishing this article anyway, because it proves:
The actual difficulties with agentic AI systems lie in various other areas, and in none of these areas does a US AI giant have more experience than most people who have been working professionally for years.
Just think about it logically: The challenges lie in the following areas:
Understanding the business
Simplifying workflows
Improving UI/UX and User Centricity
Changing ways of working
Breaking up and redesigning organizational structures
Having data in the right form at the right time in the right place
Codifying knowledge
Setting up governance properly
Building stable but modular architectures
Really good classical software engineering
etc.
Large US AI companies don’t have a long tradition in these disciplines either. That’s why they partner up with other companies, like management consultancies.
And here my perhaps somewhat political opinion regarding Germany (I’m from Germany):
We all suffered under the recession of recent years. We need hope and a spirit of optimism.
When I hear that large well-known German companies are partnering up with large well-known US AI giants, it creates incomprehension in me. Why? We have so many top people! We have all the knowledge needed to build really good agentic AI. So let’s just do it!
After finding out how banal it is to call a model, I seriously ask myself what an US AI giant brings in terms of decades-long tradition in the truly important disciplines - namely nothing at all, because these companies haven’t even existed that long!
So let’s build it ourselves. Then we also have the freedom to build with local AI when it makes sense and is important, and that might be the case more often than you think.
Now to the actual topic.
It is not a comprehensive listing or technical guide. This article is only meant to give a rough overview.
For Non-Techies: You need to have at least heard and categorized the terms. AI will play a major role in professional life in the future and you need a certain basic knowledge, just as you used to learn what the terms Deployment, CI/CD or DevOps mean.
For Engineers: You won’t learn anything new, but the next paragraph can help you get the stakeholders back on track. It happens so often in professional life that discussions move in the wrong direction and then something is debated for weeks that isn’t actually the point. Often too technical and too far removed from the business. It is very helpful when there are engineers who pull the stakeholders back in and redirect them, in the direction of: why are we building this, what is the workflow and how can we simplify it.
The right sequence is always:
Why this use case?
What is the workflow? What are the workflow steps?
What is the goal, the desired outcome? How can we simplify the workflow and still achieve the goal?
And which model do we therefore call for which workflow step?
After that: where do we host the model in the tension between performance, cost and data protection?
This order must be kept in mind.
Now to the model types.
Important: This article does NOT claim to be complete and also does NOT claim to be 100% correct. Please comment if errors have crept in and please do your own research if you need more detail. The article is only meant to help better understand the big picture.
Thank you for your understanding.
Which model types are there?
LLMs (Large Language Models)
Large language models, trained on massive text datasets to understand and generate human language
Hundreds of billions to trillions of parameters
Generalist by design: Summarizing, Analyzing, Conversation, Reasoning, Code
Use: When the task is broad, open or complex. Complex reasoning, creative text generation, multi-layered analysis, orchestration in agent systems
Examples:
GPT-4o
Claude Sonnet/Opus
Gemini
Llama 4
DeepSeek R1
Mistral Large
SLMs (Small Language Models)
Small language models with typically 1 to 13 billion parameters
Trained on focused, often domain-specific data
Can be operated locally, which simplifies governance and data protection
Significantly lower operating costs than LLMs
Use: When the task is narrowly defined and repeatable. Classification, extraction, routing, simple summaries, edge scenarios, regulated industries where compliance and data sovereignty are a priority
Examples:
Mistral 7B
Phi-3
Gemma 2B/7B
Qwen 3 4B
Code Models
Language models specifically trained or fine-tuned on source code and programming languages
Understand syntax, logic and dependencies across programming languages
Use: Code completion, code generation from natural language, debugging, refactoring, code review, test generation
Examples:
Codestral (Mistral)
StarCoder
Code Llama
DeepSeek Coder
GPT-4o (with code focus)
Embedding Models
Models that convert text, images or other data into dense numerical vectors (typically 768, 1024 or 1536 dimensions)
Semantically similar content is close together in vector space
Foundation for Retrieval Augmented Generation (RAG), semantic search and recommendation systems
Small, fast, efficient, can be operated locally
Used together with vector databases
Use: Semantic search, similarity comparisons, RAG pipelines, clustering, anomaly detection, document comparison, recommendation systems
Examples:
OpenAI text-embedding-3
NV-EmbedQA
Cohere Embed
Sentence Transformers (Open Source)
Amazon Titan Text Embeddings
Image Generation Models
Models that generate new images from text descriptions (text-to-image) or existing images
Technically based on diffusion models or transformer architectures
Use: Marketing visuals, prototyping, product photography style, illustration, design concepts
Examples:
Stable Diffusion 3.5
DALL-E 3
Midjourney
Kling 1.6 Pro
Recraft v3
Flux
VLMs (Vision Language Models)
AI systems that combine image understanding and language processing
Architecture: a visual encoder (e.g. ViT or CLIP) extracts image features, a language model (LLM) converts these into text
Can interpret images, describe them, answer questions about image content
Distinction: All VLMs are multimodal, but not all multimodal models are VLMs. VLMs are specifically focused on image plus language
Use: Document analysis (invoices, forms, scans), quality control in manufacturing, medical image evaluation, visual search, accessibility (image descriptions)
Examples:
GPT-4o (Vision)
Gemini
Claude (Vision)
LLaVA
Qwen-VL
Llama 4 Scout
Multimodal Models (LMMs / Large Multimodal Models)
Models that process and/or generate more than two modalities simultaneously: text, image, audio, video
Development is moving from text-to-text toward any-to-any models
Difference from VLMs: LMMs are the broader umbrella term and also include audio, video and other sensor data
Use: Complex workflows that require different data types simultaneously. Video analysis with text summarization, voice input with visual output, multimodal agents
Examples:
GPT-4o (Audio + Vision + Text)
Gemini 3
Meta 4M
STT / ASR (Speech to Text / Automatic Speech Recognition) and TTS (Text to Speech)
STT / ASR (Automatic Speech Recognition): Converts spoken language into written text
Supports real-time streaming and batch transcription
Features: Speaker identification, automatic punctuation, profanity filtering, custom vocabulary
TTS (Text to Speech): Converts written text into spoken language
Neural TTS models produce natural-sounding voices
Voice Cloning enables brand-specific voices
Use STT: Transcription of meetings, interviews, call centers, podcasts. Voice control. Accessibility
Use TTS: Voicebots, voice assistants, audiobook generation, conversational agents, accessibility
Examples:
OpenAI Whisper (STT, Open Source)
Google Speech-to-Text
Azure Speech
Amazon Transcribe
ElevenLabs (TTS)
OpenAI TTS
NVIDIA Riva
Azure Custom Neural Voice
Video Generation Models
Models that generate video content from text descriptions, images or short clips
Technically based on diffusion models extended for temporal coherence and motion
Results are now nearly indistinguishable from filmed material
Use: Advertising films, special effects, concept visualization, storytelling, product videos
Examples:
Sora (OpenAI)
Veo 3 (Google DeepMind)
Gen-4 (Runway)
Kling Video
NVIDIA Cosmos
Reward Models
Models trained to represent human preferences
Evaluate the quality of language model responses on a scale
Used in the RLHF process (Reinforcement Learning from Human Feedback) to steer the actual language model
Function as a bridge between human feedback and model behavior
Use: Alignment training of LLMs. Quality evaluation of model responses. Filtering and ranking of outputs. Not directly for end users, but part of the model development pipeline
Examples:
Reward Models from OpenAI
Anthropic
Nemotron-Reward (NVIDIA)
Time Series Models
Foundation models pretrained on large, cross-domain time series data
Can deliver predictions, anomaly detection and classification on new data without task-specific training (zero-shot)
Application areas: Finance, energy, healthcare, manufacturing, IoT
Limitation: Time series data is domain-specific (seasonality, trends, irregular sampling), which is why specialized models in practice are often more accurate than general foundation models
Use: Sales planning, energy demand forecasting, predictive maintenance, financial forecasting, anomaly detection in sensor data. Particularly valuable when historical data is missing or insufficient
Examples:
TimesFM 2.5 (Google)
Chronos 2 (Amazon)
MOMENT
Lag-Llama
Domain-Specific Foundation Models
Pretrained models specifically trained on data from a particular industry or domain
Difference from general LLMs: deeper understanding of domain-specific terminology, relationships and regulations
Can be fine-tuned for industry-specific downstream tasks
Use: Medicine (radiology, pathology, clinical texts), law (contract analysis, regulatory), life sciences (protein structure, genomics), finance (risk assessment, compliance), manufacturing (quality control, process optimization)
Examples:
Med-PaLM (Google, Medicine)
ESMFold (Meta, Protein Structure)
BloombergGPT (Finance)
BioMistral (Biomedicine)
SecLM (Cybersecurity)
Where do you host the model?
There are several options:
Cloud API (Managed Service): You use the model via the API of an AI model provider. The provider hosts, scales and maintains. You pay per token or per request. No own GPU requirement.
Hyperscaler Public Cloud: You run models on GPU instances at a hyperscaler. Shared infrastructure, virtually isolated. You use the hyperscaler’s ecosystem (monitoring, logging, IAM), but you are responsible for operations and scaling yourself.
Private Cloud: Dedicated, physically isolated infrastructure at a provider. Single-tenant. Only you use the hardware. Relevant when regulation requires demonstrable separation from other tenants.
Self-Hosted Cloud (own infrastructure in the cloud): You run models on rented GPU servers. Full control over model and data, but you are responsible for operations, scaling and updates.
On-Premise (local, own hardware): You run models on your own hardware in your own data center.
Decision factors: Data protection requirements, costs (per-token vs. fixed costs), latency, scaling needs, regulation, team competence.
How do you call the model?
API Endpoint (REST API): Standard way: HTTP request to an endpoint. You send a request (prompt, configuration) and receive the response. Most providers use an OpenAI-compatible API format, which is considered the de facto standard. Self-hosted solutions (Ollama, vLLM, LocalAI) also offer OpenAI-compatible endpoints, so you can replace cloud services with local models without changing code.
SDK (Software Development Kit): Libraries in Python, TypeScript, etc. that abstract the API call. Examples: OpenAI Python SDK, Anthropic SDK, LangChain, LlamaIndex.
Inference Server: For self-hosted models: a server process that loads the model and accepts requests. Frameworks: vLLM, TGI (Text Generation Inference), NVIDIA Triton, Ollama.
What it looks like in practice
Here is a very simplified example that ignores all other problems for now, this is only about the principle of calling a model.
A business user creates a report. Relevant data is loaded from internal systems beforehand. Here it is only about the step where the model is called.
Variant 1: Local model with Ollama
antwort = requests.post(
"http://localhost:11434/v1/chat/completions",
json={
"model": "mistral",
"messages": [
{
"role": "user",
"content": f"Create a document out of this data: {xyz_data}"
}
]
}
)
The model runs on your machine. No data leaves the hardware.
Variant 2: Cloud API
antwort = requests.post(
"https://api.openai.com/v1/chat/completions",
headers={"Authorization": "Bearer DEIN_API_KEY"},
json={
"model": "gpt-4o",
"messages": [
{
"role": "user",
"content": f"Create a document out of this data: {xyz_data}"
}
]
}
)
What you can see: The code is almost identical in both cases. The only difference is the URL. localhost:11434 instead of api.openai.com. That’s why it’s called OpenAI-compatible: you can switch providers without rewriting your code.
What you can do with models
For very specific requirements you can modify a model.
You can adapt it: retrain the weights with your own data so it performs better in a specific domain.
And you can optimize it: compress the weights so the model becomes smaller and runs faster.
For the vast majority of business use cases you need neither one nor the other.
Adapting and optimizing requires Machine Learning expertise, GPU infrastructure and extensive evaluation, that is expensive and slow. At the same time, the base models in 2026 are so capable that they solve most tasks without any adaptation.
The much more important thing is the architecture around it.
Still, just so you’ve heard it once:
Adapting a model
Those who need to adapt a model have the following options:
Fine-Tuning retrains all weights with a custom dataset.
LoRA freezes most weights and trains only a small additional layer.
QLoRA does the same on a compressed basis, so it runs on consumer hardware.
RLHF and DPO align the model with human preferences.
Model Merging combines the weights of multiple models without training.
Optimizing a model
Those who need to optimize a model have the following options:
Quantization reduces the numerical precision of weights and makes the model up to 75% smaller.
Pruning removes weights that contribute little.
Knowledge Distillation has a large model train a smaller one that performs similarly well.
The only open question
The only thing that really hasn’t been settled yet and I have to say, it also somewhat annoys me. There are so many professors, researchers, AI influencers and nobody defines this. Or if someone has already defined it, they haven’t told the world yet. I couldn’t find anything about it.
What is the official symbol for drawing a model?!?
Honestly, drawing little robots, asterisks or brains, I personally find very childish. I want to work professionally.
The symbol must be quickly drawable by hand, in case you’re in a meeting and drawing on a whiteboard. So all those symbols with many nodes and lines are out.
Take the cylinder for databases as a blueprint.
I hereby define the following symbol. Depending on which type of model it is, you insert different letters. Feel free to draw it a bit more beautifully:
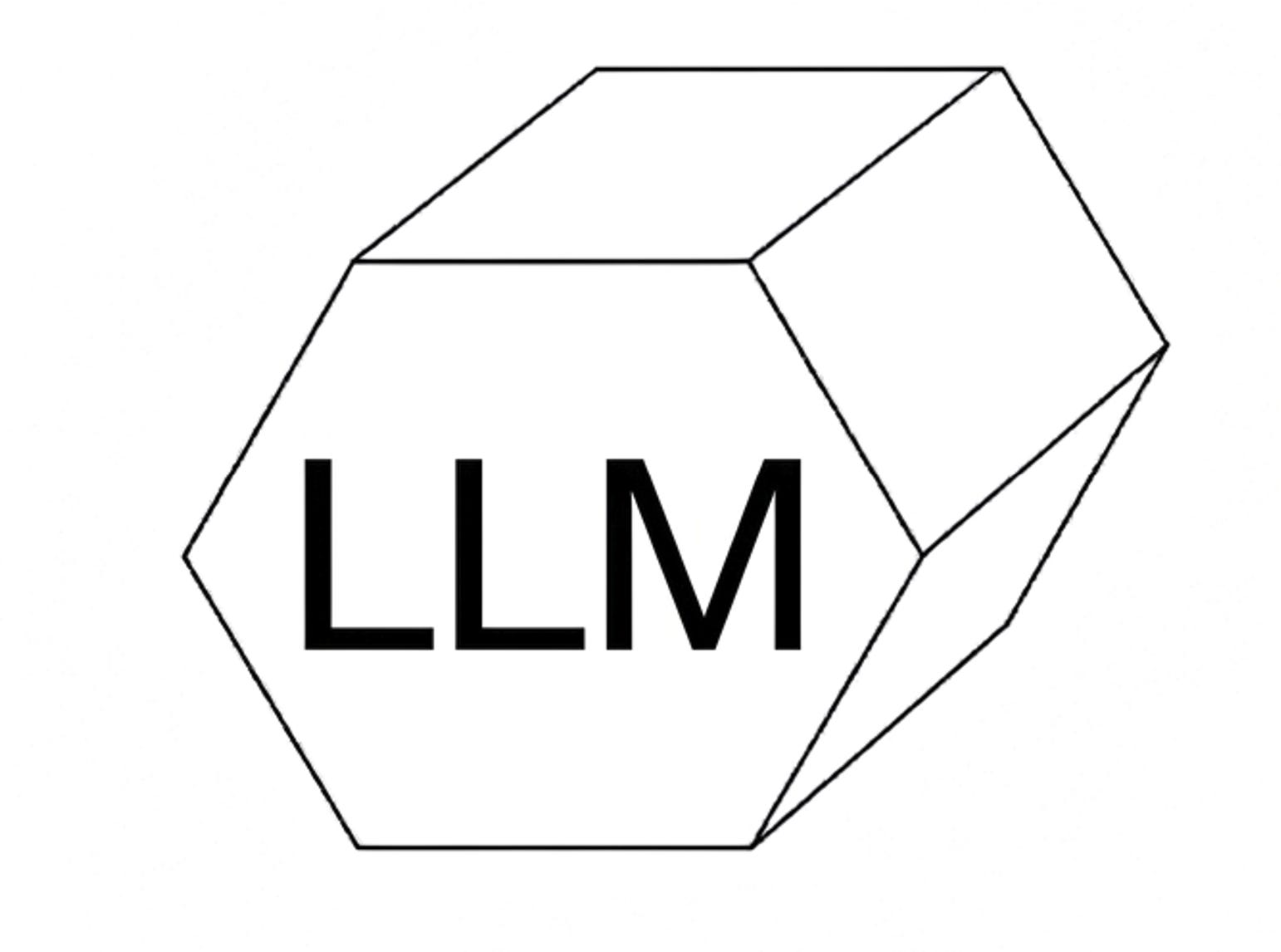
Feel free to pass this on to people who could decide it. If nobody wants to decide it, then it is hereby decided by me 😎
Conclusion
Tell me yourself, what is your conclusion after reading this article?
It’s quite interesting with the different models, but actually we have completely different questions. Right!
Look forward to the next articles!
The articles are and remain free:
or recommend them:
This is one of the best breakdowns of the AI model landscape I’ve seen, Bianca.
And your point on sovereign models is right.
Countries should absolutely build focused SLMs and domain models. But frontier-scale foundational models now require capital and compute very few countries can justify.
Even many Chinese advances are increasingly driven through distillation.
Switzerland is probably the smarter playbook here with ETH Zurich and EPFL building fully open multilingual models on national supercomputing infrastructure.
https://ethz.ch/en/news-and-events/eth-news/news/2025/07/a-language-model-built-for-the-public-good.html